How LLM Pulse Works
LLM Pulse is a platform designed to help you understand how your brand, product, or company appears inside large language models (LLMs) such as ChatGPT, Gemini, and other leading AI assistants.
Instead of relying on theoretical data or limited API outputs, LLM Pulse analyzes user-facing responses collected from public model interfaces using synthetic prompts.
These outputs do not represent real user journeys or experiences. They are controlled observations designed to support comparative and trend-based analysis.
The end result is a clear, at-a-glance view of how visible your brand is across every AI model you track. Your Overview dashboard brings together mention rate, AI Visibility Score, citations, and brand visibility trends in one place.
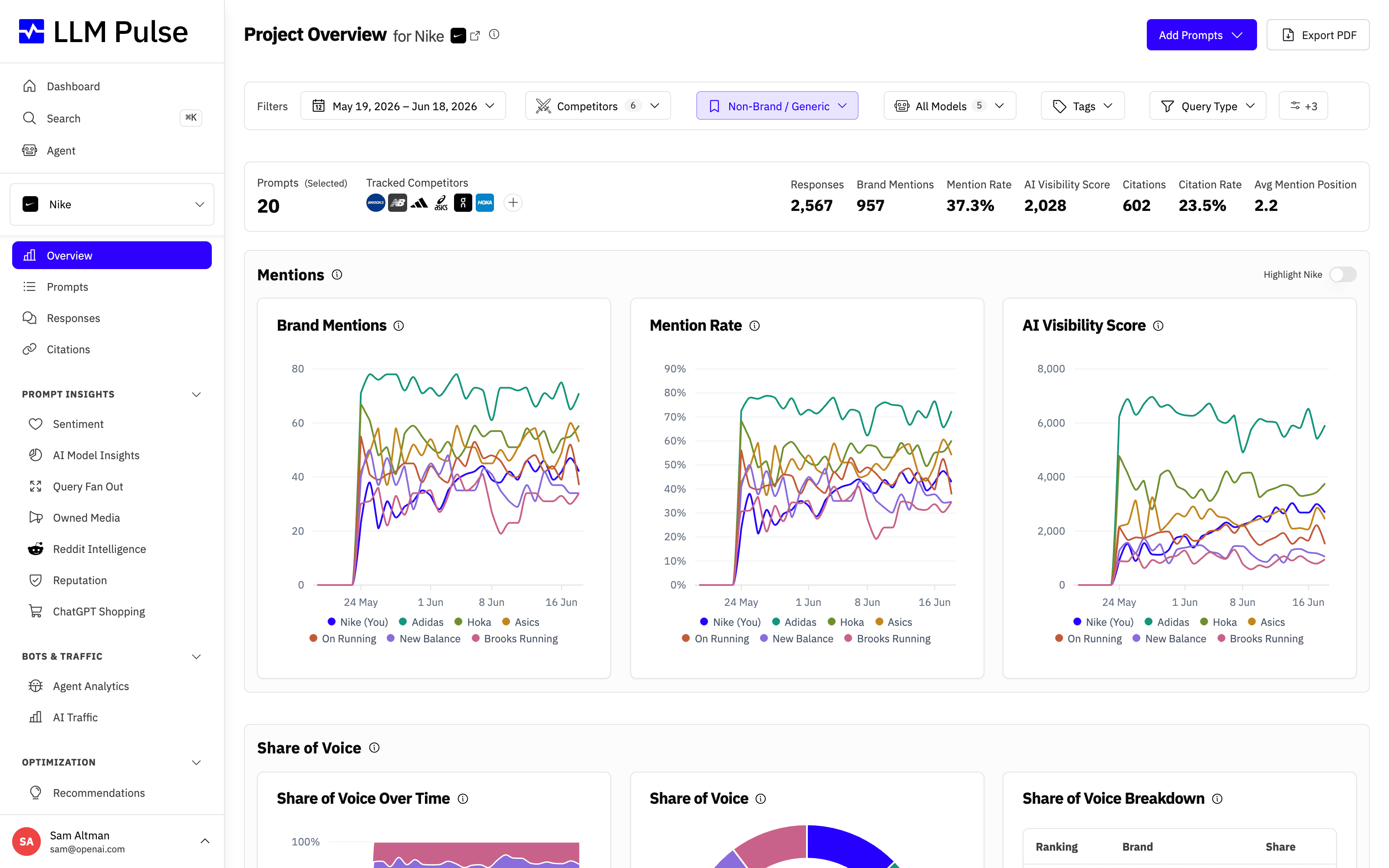
1. From Prompts to AI Responses
Everything in LLM Pulse starts with prompts.
You define or select a set of prompts that represent possible questions your potential customers, users, or prospects might ask AI models. These can include:
- Brand discovery queries
- Product comparisons
- Category searches
- Reputation-related questions
- Purchase-intent prompts
- Informational or educational queries
Once your prompts are configured, LLM Pulse automatically submits them to different LLM platforms through their public user interfaces.
We do not simulate API calls. We reproduce real user interactions.
This means the system collects the same type of answers that a human would see when using these tools.
2. UI-Based Data Collection (Not APIs)
LLM Pulse gathers data by scraping and monitoring the public web interfaces of LLM platforms.
We intentionally do not use official APIs for analysis.
Why?
APIs often:
- Provide simplified or truncated outputs
- Apply different ranking or formatting rules
- Exclude citations, links, and contextual elements
- Do not reflect the real user experience
By working at the UI level, LLM Pulse captures:
- Full answers
- Highlighted entities and references
- Linked sources
- Product cards and panels
- Visual elements when available
- Ordering and positioning of brands
This approach allows us to analyze how your brand truly appears “in the wild.”
3. Response Processing and Normalization
Once responses are collected, LLM Pulse processes them through several normalization steps.
This includes:
- Cleaning and structuring raw outputs
- Identifying brands, products, and entities
- Extracting mentions and citations
- Detecting links and references
- Standardizing formats across platforms
Different LLMs present information in different ways. Our system converts these heterogeneous formats into a unified analytical structure.
This makes cross-model comparisons possible.
4. Data Analysis and Metrics Engine
After normalization, all responses are sent to LLM Pulse’s analytics engine.
Here, we transform raw answers into actionable metrics.
Typical analyses include:
- Brand Presence
- How often your brand appears
- In which positions
- In which contexts
- Against which competitors
- Citations and Sources
- Which domains are cited
- How frequently
- In which scenarios
- With what authority
- Share of Voice
- Your visibility versus competitors
- Category-level dominance
- Prompt-level distribution
- Sentiment and Framing
- How your brand is described
- Positive, neutral, or negative framing
- Recurring narratives
- Reputation patterns
- Positioning and Ranking
- Top mentions
- First recommendations
- Comparison outcomes
- Preferred alternatives
All metrics are computed using consistent methodologies across models and time periods.
5. Synthetic Prompts and Probabilistic Nature of LLMs
All prompts used in LLM Pulse are synthetic.
In fact, all prompts used in LLM Pulse and in every other LLM monitoring tool on the market are synthetic, by necessity.
This means they are carefully designed to represent realistic user intents, based on market research, industry knowledge, and common search patterns. However, there is no technical way to know exactly what users ask, how they phrase their questions, or in which context they interact with LLMs.
Real user conversations with AI systems are private and inaccessible.
As a result:
- LLM Pulse does not observe real user queries
- All tracked prompts are estimations
- Prompt sets are models of reality, not exact replicas
- In addition, all LLM responses are probabilistic by nature.
- Language models generate answers based on probability distributions, context, and internal weighting. This means that:
- The same prompt can generate different answers at different times
- Outputs may vary across sessions, users, or locations
- Small changes in context can affect rankings and recommendations
Because of this, LLM-generated content is inherently non-deterministic.
6. Data as Directional, Not Absolute Truth
LLM Pulse does not provide absolute truths.
It provides statistically grounded, directional insights derived from repeated observations.
All metrics and visualizations represent:
- Estimated visibility
- Relative positioning
- Probabilistic trends
- Comparative signals
They are designed to support strategic decision-making, not to serve as definitive measurements.
LLM Pulse helps you answer questions such as:
- “Am I becoming more visible over time?”
- “Am I gaining ground versus competitors?”
- “Is my reputation improving or degrading?”
- “Which content seems to influence AI answers?”
It does not claim to measure reality with perfect precision.
Instead, it provides a structured analytical framework to support informed decision-making under uncertainty.
7. Historical Tracking and Trend Analysis
LLM Pulse continuously re-runs prompts over time.
By default, prompt tracking runs weekly, which enables time-series comparisons.
This allows you to:
- Monitor changes in visibility
- Detect early reputation risks
- Track competitor movements
- Estimate the impact of SEO, PR, brand awareness, and content initiatives
- Observe model updates and output shifts over time
Each run is stored and versioned, which supports long-term trend analysis.
8. Dashboards and Reporting
All processed data is visualized in the LLM Pulse dashboard.
You can:
- Explore prompt-level results
- Compare models side by side
- Filter by brand, category, or region
- Export reports
- Connect data to external BI tools
This makes LLM Pulse suitable for founders, marketers, SEO / GEO teams, agencies, and enterprise analytics teams.
9. Privacy, Compliance, and Ethics
LLM Pulse only analyzes publicly accessible interfaces and publicly available responses.
We:
- Do not access private user accounts
- Do not collect personal data
- Do not interfere with platform operations
- Respect applicable legal and compliance standards
Our goal is to observe, not manipulate.
10. Why This Architecture Matters
The core value of LLM Pulse lies in its end-to-end pipeline:
Prompts → Real Interfaces → Answers → Normalized Data → Actionable Insights
This architecture ensures:
- Broad coverage across models
- Practical relevance
- Long-term comparability
- Strategic decision support
Compared to many API-based approaches, LLM Pulse focuses on analyzing user-facing outputs collected via public interfaces.
This helps teams study how visibility, positioning, and citations can evolve over time across different models, using a repeatable prompt set.
It does not measure user perception, discovery, or purchasing behavior directly.
11. Summary
LLM Pulse works by:
- Running synthetic prompts on public LLM interfaces
- Collecting user-facing responses
- Structuring and normalizing outputs
- Applying comparative and trend-based analysis
- Presenting estimated signals in dashboards and reports
All outputs are based on modeled prompts and probabilistic responses.
They do not represent real user behavior, real queries, or objective reality.
They represent analytical approximations designed to support strategic reasoning and decision-making under uncertainty.